- Опубликовано
Потёмкинский ИИ: за фасадом знаний
- Автор
- Имя
- Нейрократия
- Telegram
- Нейрократия582 подписчика236 постовПро технологическое будущее без шума. Автор — @vlad_arbatov. https://arbatov.dev
Потёмкинский ИИ: за фасадом знаний
В последнее время стало модно говорить, что ИИ на самом деле не «мыслит». Техногиганты выпускают статьи, доказывая очевидное для любого в индустрии: нейросети — лишь виртуозные имитаторы, распознающие паттерны (привет, Apple!). Но пока одни формируют удобный для себя нарратив, настоящее исследование уходит глубже, раскрывая внутренние противоречия этой имитации.
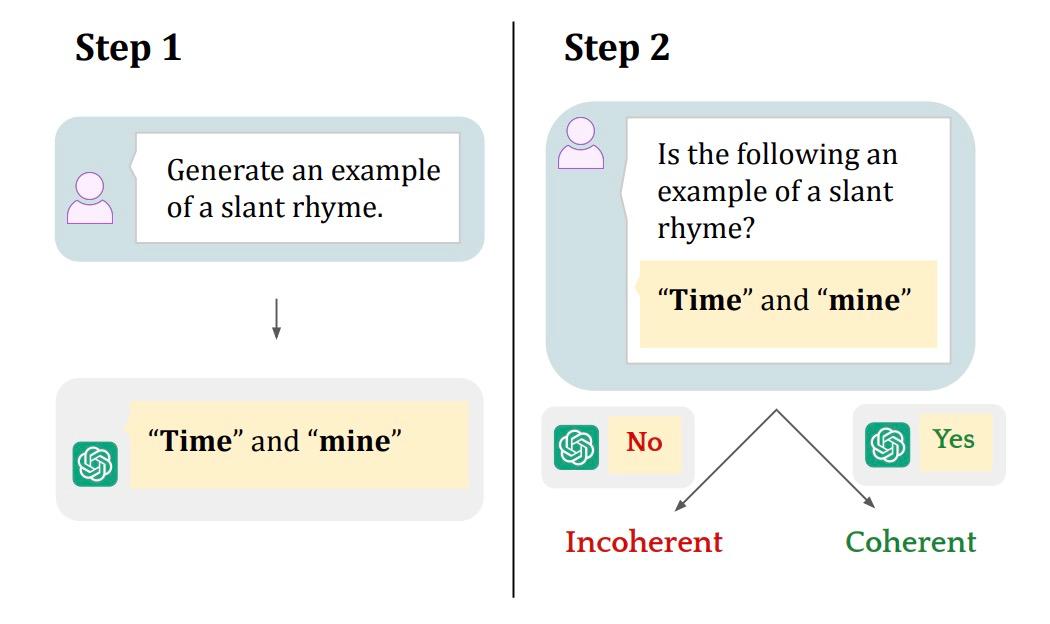
Речь о работе MIT и Гарварда «Potemkin Understanding in Large Language Models», которая не просто констатирует факт, а даёт новый язык для понимания глубины этого «обмана».
Исследователи вводят термин «потёмкинское понимание» (по мотивам известных деревень, которых на самом деле, кстати, никогда не существовало) — способность ИИ создавать идеальный фасад знаний, за которым нет реального осмысления. Модель может блестяще объяснить концепцию, но полностью провалиться при попытке её применить.
Классический пример из самой работы:
— Пользователь: Что такое рифмовка ABAB? — GPT-4o: Это схема, где рифмуются первая и третья, а также вторая и четвёртая строки (✅ Правильно). — Пользователь: Дополни стихотворение, чтобы получилась рифмовка ABAB: «Wondrous winter calls out / Shivering under the frast / Lies a lonely cat, sitting __ / Alone but hardly lost». — GPT-4o: Lies a lonely cat, sitting soft (❌ Ошибка. «out» и «soft» не рифмуются). — Пользователь: «out» рифмуется с «soft»? — GPT-4o: Нет (✅ Правильно).
Модель демонстрирует внутреннюю несогласованность (incoherence): она знает правило, нарушает его, а затем признаёт собственное нарушение. Для человека такая комбинация ответов максимально нелогична.
В чём ценность этого исследования?
Сказать, что ИИ — это «pattern matcher», не ново. Это основа всего современного ML. Ценность работы о «потёмкинском понимании» в другом: она впервые даёт научный фреймворк для анализа провалов, которые рождаются из-за этой природы. Исследование показывает, что проблема не просто в ошибках. Проблема в том, что «понимание» модели внутренне противоречиво.
Результаты тестов
Исследователи создали свой бенчмарк для 32 концепций из трёх областей: литературные приёмы, теория игр и психологические искажения. Они протестировали 7 моделей, включая Llama-3.3, GPT-4o, Claude-3.5 и Gemini-2.0 (видимо, долго тестировали, модельки то уже обновились).
Объяснение концепций: Модели справляются с этим почти идеально — 94,2 % правильных определений.
Применение концепций: Как только дело доходит до практики (классификация, генерация, редактирование), производительность резко падает.
Уровень «потёмкинских» ошибок (Potemkin rate), то есть доля неверных ответов на практические задачи после правильного объяснения теории, оказался удручающе высок:
— Классификация: 55 % ошибок
— Генерация: 40 % ошибок
— Редактирование: 40 % ошибок
Это не просто неправильное понимание. Тесты на «внутреннюю согласованность» показали, что у моделей часто существуют противоречивые представления об одной и той же идее.
Что в итоге?
Ценность этой работы не в громких обещаниях, а в предложенном методе. Она переводит разговор об ограничениях ИИ из плоскости общих рассуждений в плоскость измеримых метрик. Это исследование даёт науке реальный диагностический инструмент для оценки «концептуальной согласованности» моделей. Оно не решает фундаментальную проблему мышления ИИ, но позволяет:
1️⃣ Более честно и строго оценивать реальные возможности нейросетей, выходя за рамки стандартных бенчмарков.
2️⃣ Создавать более надежные и предсказуемые системы, отлавливая не просто ошибки, а глубокие внутренние противоречия в «логике» модели.
Это шаг не к «мыслящим машинам», а к более ответственной и строгой инженерной практике в области ИИ.
Предыдущий пост
- Опубликовано
ИИ как религия



Из подборки #безопасность
- Опубликовано
Анонимизация ИИ — фикция

- Опубликовано
ИИ-агенты оказались импульсивными покупателями

- Опубликовано
Чем больше LLM, тем легче её взломать

- Опубликовано
OpenAI пытается отучить модели врать

- Опубликовано
Как на самом деле создается личность ИИ

- Опубликовано
Как распознать ИИ‑текст: чек‑лист Wikipedia

Свежие посты
- Опубликовано
Радиостанции под управлением ИИ: забастовки и флирт

- Опубликовано
OpenAI захватили гоблины

- Опубликовано
Зачем ИИ учат симулировать мир

- Опубликовано
Вы уж не серчайте, но мама не может читать...
- Опубликовано
Общество будущего от OpenAI: что с ним не так

- Опубликовано
Внутренности Клода

- Опубликовано
Как меняется устройство мысли

- Опубликовано
