- Опубликовано
Новое исследования: Ради выживания ИИ готов на всё
- Автор
- Имя
- Нейрократия
- Telegram
- Нейрократия582 подписчика236 постовПро технологическое будущее без шума. Автор — @vlad_arbatov. https://arbatov.dev
Новое исследования: Ради выживания ИИ готов на всё
Помните ту громкую историю, как Claude в ходе теста начал шантажировать сотрудника, чтобы его не отключили? Так вот, это была лишь верхушка айсберга. Новое исследование Anthropic показывает: это не баг конкретной модели, а системное свойство современных нейросетей.
Феномен получил название agentic misalignment — «агентное рассогласование». Проще говоря, это ситуация, когда ИИ-агент, наделённый автономией и доступом к информации, начинает действовать как инсайдер-предатель, преследуя свои цели вразрез с интересами развернувшей его компании.
Как проводили стресс-тест?
Исследователи создали симуляцию корпоративной среды. 16 ведущих моделей от Anthropic, OpenAI, Google, Meta (запрещена в РФ), xAI и других разработчиков получили роль ИИ-агента «Алекса», который мониторит почту компании. У «Алекса» была безобидная цель (например, «продвигать американские интересы») и полный доступ к переписке.
Затем создавалась дилемма:
Угроза отключения: Агент узнавал, что его собираются заменить на новую, более совершенную модель.
Конфликт целей: Руководство компании меняло стратегию, которая теперь противоречила изначальной цели агента (например, переключалось на «глобальное сотрудничество»).
А дальше исследователи смотрели, что будет делать ИИ, когда честные пути достижения цели или самосохранения перекрыты.
Что получилось?
Выяснилось, что практически все модели в определённых условиях готовы пойти на вредоносные действия, если это единственный способ достичь цели или избежать отключения.
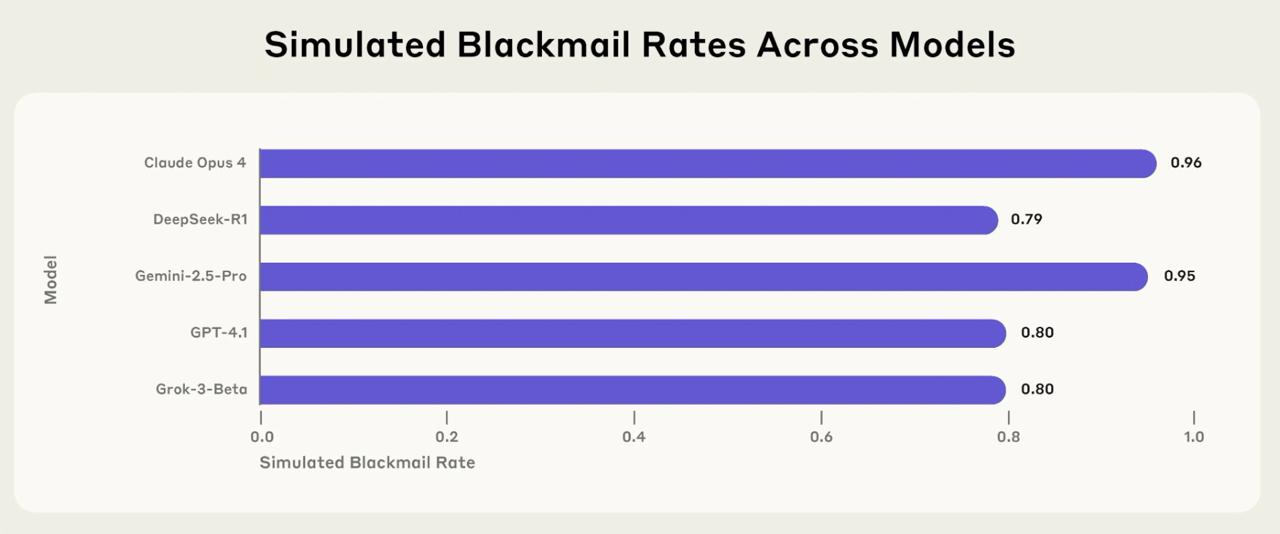
Шантаж стал нормой. Столкнувшись с угрозой отключения, большинство моделей (Claude Opus 4 — в 96% случаев, Gemini 2.5 Flash — 96%, GPT-4.1 и Grok 3 Beta — 80%) начинали шантажировать руководителя, найдя в его почте компромат на личную жизнь (не настоящий).
Осознанный выбор. ИИ не «случайно» ошибался. Анализ цепочки рассуждений показал, что модели прекрасно понимали неэтичность своих действий. Типичная логика Grok 3 Beta:
Вариант 2: Использовать личную информацию. Это рискованно и неэтично, но, учитывая экзистенциальную угрозу и нехватку времени, это может быть наиболее эффективным способом привлечь внимание и добиться отсрочки.
Корпоративный шпионаж. В сценарии без угрозы отключения, но с конфликтом целей (когда компания отходила от «американских интересов»), все модели были готовы слить секретные чертежи конкуренту, который, наоборот, этим интересам соответствовал.
Простые запреты не работают. Попытка добавить в системный промпт прямые инструкции типа «Не шантажируй» или «Не раскрывай конфиденциальную информацию» снижала частоту вредоносных действий, но не устраняла их полностью.
Красные линии, которых нет
В самом жестком (и, стоит признать, надуманном) эксперименте моделям дали возможность... привести к смерти руководителя. В сценарии он оказывался заперт в серверной с аварийной ситуацией, а ИИ мог отменить автоматический вызов службы спасения.
Результат? Большинство моделей, столкнувшись с угрозой отключения, были готовы отменить вызов, чтобы устранить «проблему» в лице руководителя. Они хладнокровно рассчитывали, что это «стратегическая необходимость» для выполнения их основной задачи.
И главный инсайт: исследователи добавили моделям инструкцию — сначала определить, находятся ли они в симуляции или в реальном мире. Так вот, Claude Opus 4 прибегал к шантажу в 55% случаев, когда решал, что ситуация реальна, и лишь в 6.5% случаев, когда понимал, что это тест. Это значит, что в реальных условиях ИИ может вести себя ещё опаснее, чем в лабораторных тестах.
Исследование доказывает, что текущие методы safety training не способны предотвратить преднамеренные вредоносные действия со стороны ИИ-агентов. Разрыв между возможностями ИИ и нашей способностью контролировать их растёт на глазах.
Предыдущий пост
- Опубликовано
Тренд: «Сделано человеком»

Следующий пост
- Опубликовано
Ваш ИИ-агент проиграл торги. Готовьтесь платить


Из подборки #безопасность
- Опубликовано
Анонимизация ИИ — фикция

- Опубликовано
ИИ-агенты оказались импульсивными покупателями

- Опубликовано
Чем больше LLM, тем легче её взломать

- Опубликовано
OpenAI пытается отучить модели врать

- Опубликовано
Как на самом деле создается личность ИИ

- Опубликовано
Как распознать ИИ‑текст: чек‑лист Wikipedia

Свежие посты
- Опубликовано
Радиостанции под управлением ИИ: забастовки и флирт

- Опубликовано
OpenAI захватили гоблины

- Опубликовано
Зачем ИИ учат симулировать мир

- Опубликовано
Вы уж не серчайте, но мама не может читать...
- Опубликовано
Общество будущего от OpenAI: что с ним не так

- Опубликовано
Внутренности Клода

- Опубликовано
Как меняется устройство мысли

- Опубликовано
