- Опубликовано
Коллективный разум для Claude
- Автор
- Имя
- Нейрократия
- Telegram
- Нейрократия582 подписчика236 постовПро технологическое будущее без шума. Автор — @vlad_arbatov. https://arbatov.dev
Коллективный разум для Claude
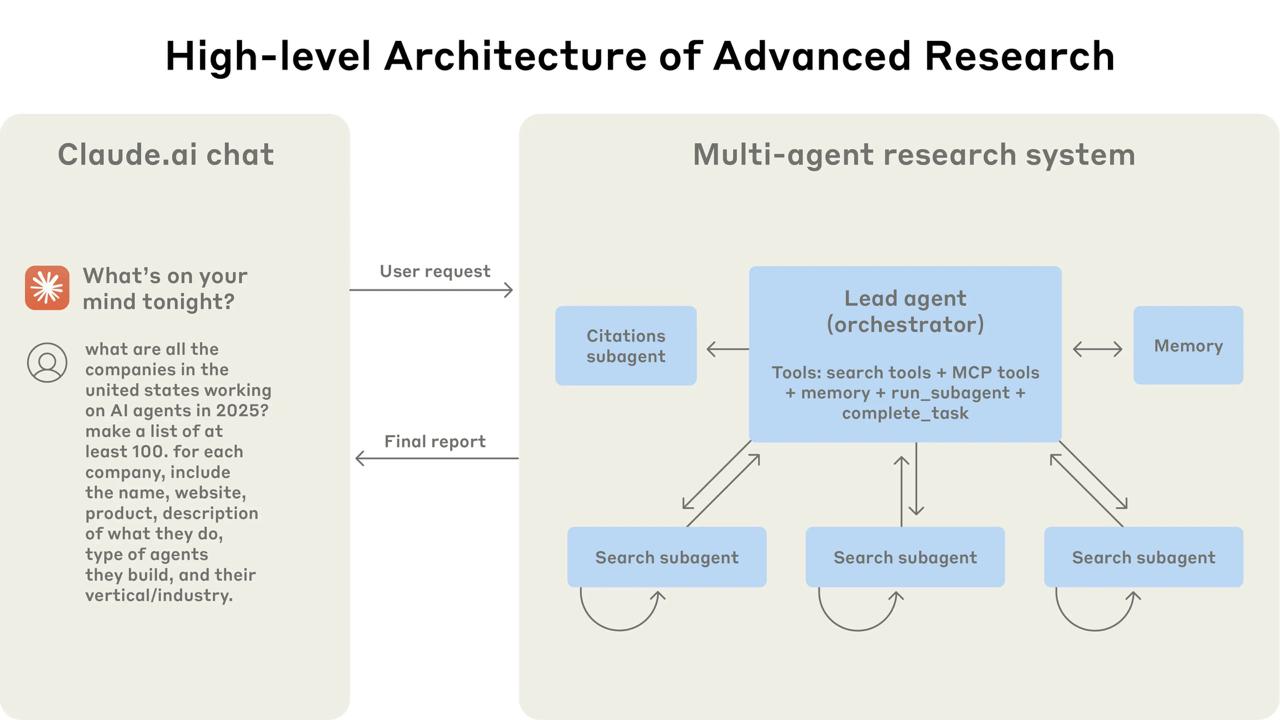
Anthropic показала, как строит свои мультиагентные системы
Anthropic выкатила подробнейший разбор своей фичи Research — мультиагентной системы, которая позволяет Claude проводить сложные исследования, используя команду ИИ-агентов. Это довольно глубокий взгляд на архитектуру ИИ-систем нового поколения, где задачи решаются скоординированной группой субъектов.
Что это такое и зачем нужно?
В основе системы лежит архитектура «оркестратор-исполнитель». Один «главный» агент (Lead-агент на базе Claude 4 Opus) анализирует сложный запрос пользователя, декомпозирует его на подзадачи и запускает несколько «рабочих» субагентов (на базе Claude 4 Sonnet), которые работают параллельно. Каждый субагент копает свою часть информации в вебе или других источниках, отфильтровывает самое важное и возвращает результат «дирижеру» для сборки финального отчета.
Внутренние тесты Anthropic показали, что такая мультиагентная система превосходит по производительности одиночного Claude 4 Opus на 90.2%. Ключевой инсайт, который они выявили: производительность на 80% зависит от количества использованных токенов. Проще говоря, чтобы решить сложную проблему, нужно «потратить» на нее достаточно «мыслей».
Цена вопроса: сжигая токены во имя результата
Но, как всегда, есть нюанс™. Такие системы — настоящие пожиратели ресурсов. По данным Anthropic, мультиагентные операции расходуют примерно в 15 раз больше токенов, чем обычные чат-взаимодействия.
Это делает их экономически оправданными только для задач высокой ценности, где результат стоит затрат. Кроме того, они плохо подходят для задач, которые плохо распараллеливаются, — например, для большинства задач по программированию, где все части кода тесно связаны.
По теме: → Вайб-кодинг — это зависимость
Как заставить их работать вместе? Принципы от Anthropic
Самое ценное в публикации — это уроки, извлеченные командой при создании системы:
🔸 Грамотное делегирование. Главный агент должен ставить субагентам максимально четкие и детальные задачи. Простые инструкции вроде «изучи дефицит полупроводников» приводили к тому, что агенты дублировали работу друг друга или уходили не в ту степь.
🔸 Масштабирование усилий. В промпты встроили правила для оценки сложности задачи. Простой факт-чекинг — 1 агент и 3-10 вызовов инструментов. Сложное исследование — 10+ субагентов с четко разделенными ролями.
🔸 Инструменты решают. Качество описания инструментов, к которым обращаются агенты, критически важно. Плохое описание может отправить агента по совершенно ложному пути.
🔸 Самосовершенствование агентов. Пожалуй, самый поразительный пункт. Anthropic создали специального агента-тестировщика. Он брал инструмент с плохим описанием, пытался его использовать, раз за разом терпел неудачу, а затем... сам переписывал его описание, чтобы избежать ошибок в будущем. Этот мета-процесс позволил сократить время выполнения задач другими агентами на 40%.
🔸 Параллельность — ключ к скорости. Запуск субагентов и их инструментов в параллельном режиме сократил время выполнения сложных запросов на 90% — с часов до минут.
Как это всё оценивать?
Оценка таких систем — отдельная головная боль. Они недетерминированы: на один и тот же запрос два запуска могут выдать одинаково правильный ответ, но прийти к нему совершенно разными путями. Поэтому оценивать нужно не процесс, а конечный результат.
Для этого в Anthropic активно используют LLM-as-judge (нейросеть в роли оценщика), но подчеркивают, что без ручного тестирования живыми людьми никуда. Именно люди заметили, что ранние версии агентов предпочитали SEO-оптимизированные сайты-помойки авторитетным научным PDF.
Статья Anthropic — это честный взгляд на то, насколько огромен разрыв между работающим прототипом и надежной продакшн-системой в мире ИИ-агентов. Проблемы стейтфул-систем, каскадные ошибки, сложность отладки и развертывания — все это здесь умножается на непредсказуемость самих моделей.
Предыдущий пост
- Опубликовано
Технологический трансгуманизм: спасение или манипуляция?



Из подборки #обзор
- Опубликовано
AI 2025: агенты, ролплей, китайская экспансия

- Опубликовано
Чем больше LLM, тем легче её взломать

- Опубликовано
OpenAI пытается отучить модели врать

- Опубликовано
Как ИИ создаёт видео: разбираем технологию

- Опубликовано
Activepieces: новый n8n?

- Опубликовано
Anthropic запустила образовательные курсы

Свежие посты
- Опубликовано
Радиостанции под управлением ИИ: забастовки и флирт

- Опубликовано
OpenAI захватили гоблины

- Опубликовано
Зачем ИИ учат симулировать мир

- Опубликовано
Вы уж не серчайте, но мама не может читать...
- Опубликовано
Общество будущего от OpenAI: что с ним не так

- Опубликовано
Внутренности Клода

- Опубликовано
Как меняется устройство мысли

- Опубликовано
